
빅데이터분석기사 필기 정리
Intro
-
프로젝트 작업을 진행하려 했으나, 빅데이터분석기사 시험이 10월 2일 인것이 시험 하루 전인 오늘 기억나서 급하게 정리해보려 한다.
-
정리 내용은 이 글의 기출 문제 및 인터넷 이곳 저곳에서 본 기출문제 복원본들의 키워드들에 대한 개념을 정리하는 방식으로 진행했다.
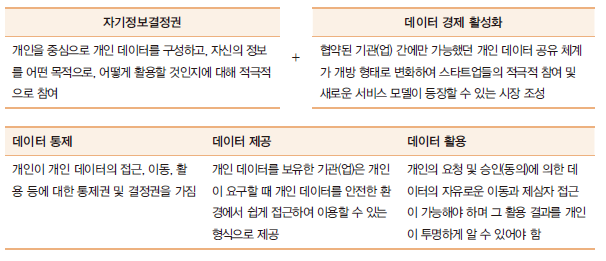
개인정보 동의


빅데이터 분석의 4가지 단계

- 묘사 분석
- 과거에 무슨 일이 있었는지, 현재 무슨일이 일어나는지 정확히 분석하는것.
- 어떤 일이 일어났는가?
- 진단 분석
- 묘사 분석에서 찾아낸 분석 내용이 왜 일어났는지 원인을 이해하는 과정.
- 왜 일어났는가?
- 예측 분석
- 데이터를 통해 기업/조직의 미래, 고객의 행동 등을 예측하는 과정.
- 무슨 일이 일어날 것인가?
- 처방 분석
- 예측 분석 결과를 기반으로 이루어지는 최적화 과정.
- 우리는 무엇을 해야할 것인가?
ETL
-
Extraction(추출), Transform(변환), Load(적재)
-
데이터를 추출하고, 가공해서, 가공한 데이터를 저장하는 과정.
데이터 전처리 절차
- 데이터 정제 -> 결측값 처리 -> 이상값 처리 -> 분석변수처리
프로세스와 절차의 차이
- 프로세스(Process)
- 정의
- 입력을 출력으로 변환시키는 상호 관련되거나 상호 작용하는 활동, 행동 및 자원의 집합으로 Result를 달성
- 특징
- 프로세스의 입력은 일반적으로 다른 프로세스의 출력
- 조직에서의 프로세스는 일반적으로 가치를 부가하기 위하여 통제된 조건 하에서 계획되고 수행됨
- 요구되는 출력을 창출, 동적인 ‘현상’임
- 요구되는 프로세스 출력을 창출하는데 필요한 활동을 수행하는 인원에게 제공되는 절차 및 자원이 요구됨.
- 정의
- 절차(Procedure)
- 정의
- 활동 또는 프로세스를 수행하기 위해 규정된 방식
- 구성
- 목적
- 범위 및 적용
- 용어 정의
- 입력사항
- 활동
- 출력사항
- 참조문서
- 절차서
- 절차를 문서화한 자료
- 특징
- 임무를 완수하기 위해 일하는 방법. 정적인 ‘문서화’
- 적격성, 권한 및 자원이 갖추어진 인원이 사용할 경우에만 출력을 창출
- 정의
상향식 접근법과 하향식 접근법
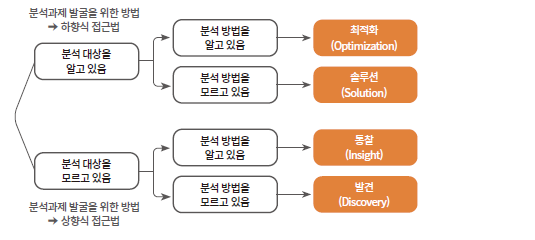
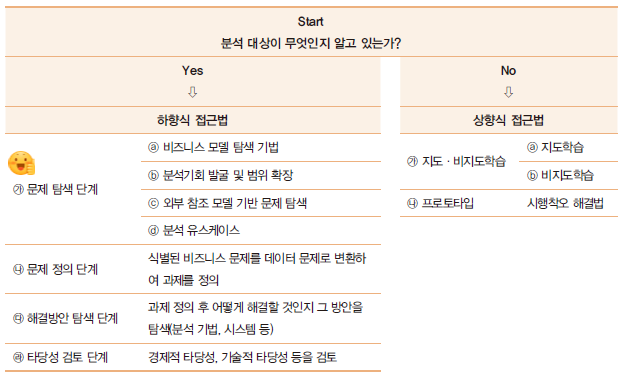
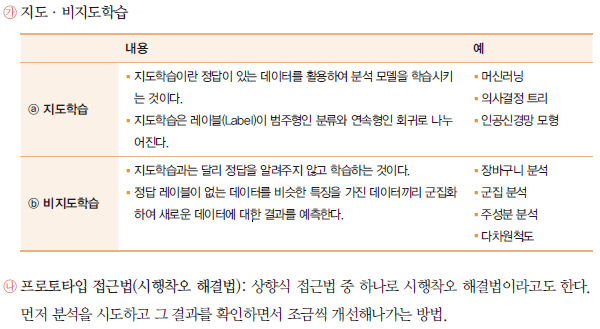
- 상향식 분석과제 발굴 방법론
데이터의 유형
- 데이터의 유형
- 정형 데이터(Structured data)
- 정해진 규칙에 맞게 들어간 데이터중 수치만으로 의미 파악이 쉬운 데이터
- 값이 의미를 파악하기 쉽고, 규칙적인 값으로 들어온 데이터
- 비정형 데이터(Unstructured data)
- 정해진 규칙이 없는 데이터.
- 텍스트, 음성, 영상 데이터 등이 해당됨.
- 반정형 데이터(Semi-structured data)
- 구조를 가진 데이터
- JSON, XML, HTML등의 포맷이 해당됨.
- 정형 데이터(Structured data)
개인정보 비식별화 기법
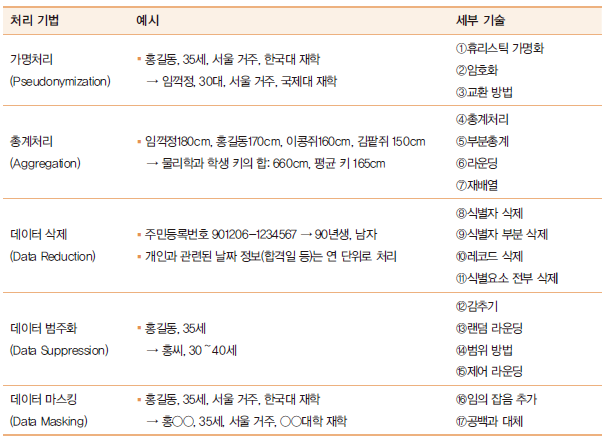
- 식별자
- 개인을 식별할수 있는 속성.
- 전화번호, 이름, 이메일 등.
- 비식별 조치시 무조건 삭제되어야 함.
- 준식별자
- 자체로는 식별자가 아니지만, 다른 데이터와의 결합을 통해 특정 개인을 추론할수 있는 속성.
- 거주 도시명, 몸무게, 혈액형 등.
- 비식별화 기법에서 변형/조작의 대상이 됨.
- 민감정보
- 개인의 사생활이 드러날수 있는 속성.
- 병명, 예금 잔고, 카드 결제 액 등.
- 데이터 분석시 주로 측정되는 대상이며, 현대적 비식별화 기법에서 값이 보존됨.
- K-익명성
- 식별자가 삭제된 데이터라도 준식별자들의 조합을 통해 배포된 데이터의 개인이 추론되어 민감정보가 유출될수 있음.(연결 공격)
- 한 개인이 k-l명의 다른 레코드와 구별되지 않아야 한다.
- L-다양성
- K-익명성을 만족하더라도 동질성 공격에 취약할수 있음.
- 각 블록이 적어도 l개의 다양한 민감정보를 가지고 있어야 한다.
- T-근접성
- L-다양성을 만족하더라도 모집단 대비 민감한 정보의 분포 차이를 통해 개인 사생활 정보가 노출되는 문제가 발생할수 있음.
- 데이터 집합에서 구별되지 않는 레코드들의 민감한 정보의 분포와 전체 데이터의 민감한 정보의 분포의 차이를 t이하로 만들어 프라이버시를 보호하는 모델.
딥러닝에 관한 설명으로 옳은 것
- 드롭아웃
- 오버피팅 문제를 해결하기 위해 인위적으로 무작위 뉴런의 작동을 중지시키는것.
- 역전파 알고리즘(back propagation)
- 기존 가중치를 사용해 오차를 계산하고,
- 전체 오차를 각 가중치로 편미분한 값을 기존 가중치에서 빼주어 오차를 줄여주는 과정을 output에 가까운 레이어부터 실행
- 이러한 과정을 통해 예측에 대한 오차를 줄여 예측이 정답에 가까워지도록 학습시킨다.
- 활성화 함수
-
입력된 데이터의 가중치 합을 출력 신호로 변환하는 함수.
-
가중치 합의 크기에 따라 활성 여부가 결정된다.
-
시그모이드(Sigmoid)

-
입력값에 따라 0 또는 1을 출력하는 함수.
-
정의역의 절댓값이 커질수록 미분값이 0으로 수렴한다.
- Gradient Vanishing 발생 가능성 있음
-
-
ReLU
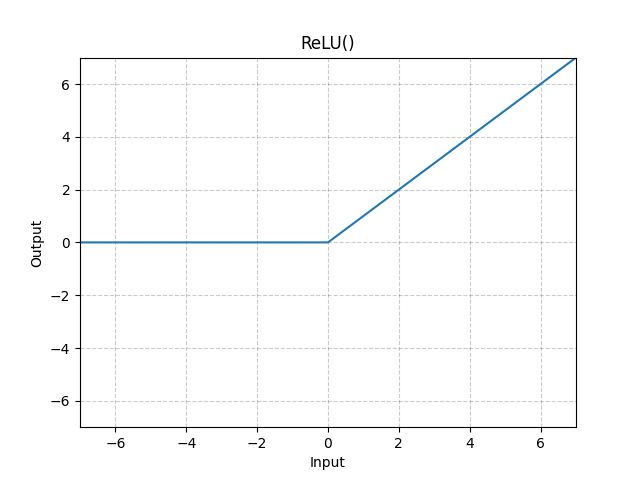
-
입력값이 0보다 작으면 0을, 0보다 크면 입력값 그대로 출력하는 함수.
-
정의역의 절댓값이 커져도 미분값은 유지되므로 Gradient Vanishing문제는 해결됨.
-
하지만 가중치 합이 음수인 노드들은 출력값이 0이 되어버려 그대로 죽어버리는 Dying Relu 현상이 발생함.
- 이를 보완하기 위해 0이하의 출력값에서도 기울기를 가지는 leaky ReLU, PReLU등이 등장함.
-
-
잔차(residual)와 오차(error)
- 잔차(residual)
- 표본집단에서 회귀식을 얻고, 회귀식을 통해 얻은 예측값과 실제 관측값의 차이.
- 오차(error)
- 모집단에서 회귀식을 얻고, 회귀식을 통해 얻은 예측값과 실제 관측값의 차이
민감도와 특이도
- 어떤 질병을 검사하는 새로운 검사법이 나왔을때, 검사 결과는 다음과 같이 나올것이다.

- 이때, 민감도와 특이도는 다음과 같이 정의된다.
- 민감도
- 양성인 사람 중 올바른 양성의 비율
- 즉, 검사가 제대로 양성을 판별한 경우의 비율
- ① / ①+②
- 특이도
- 음성인 사람중 올바른 음성의 비율
- 즉, 검사가 제대로 정상인을 판별한 경우의 비율
- ④ / ③+④
- 민감도
- ROC 그래프
- x축을 1-특이도, y축을 민감도로 설정했을때 데이터가 그리는 곡선.
- ROC 곡선에서 곡선 밑 면적(AUC)의 넓이가 넓을수록 해당 검사도구의 정확도가 높다.
잡설
-
오늘 SQLD와 리눅스마스터 2급의 시험 결과가 나왔다.
- SQLD는 합격, 리눅스마스터는 불합격했다.
-
공부하면서 느낀건데, 전문대 출신이라 이산수학같은 기반 지식이 없는것이 상당히 뼈아프게 느껴졌다.