
프로젝트_랜드마크 - 21일차
Intro
-
프로젝트를 완성했다고 선언하기는 했으나, 아직 개선점들이 보이는것 같아 오늘은 간략하게 프로젝트 전체를 되짚어보고, 성찰 및 반성의 시간을 가져보기로 했다.
-
프로젝트 1일차의 글과 20일차의 완성본을 비교해보고, 개선점 및 제작 과정에서의 피드백을 스스로 넣어보기로 했다.
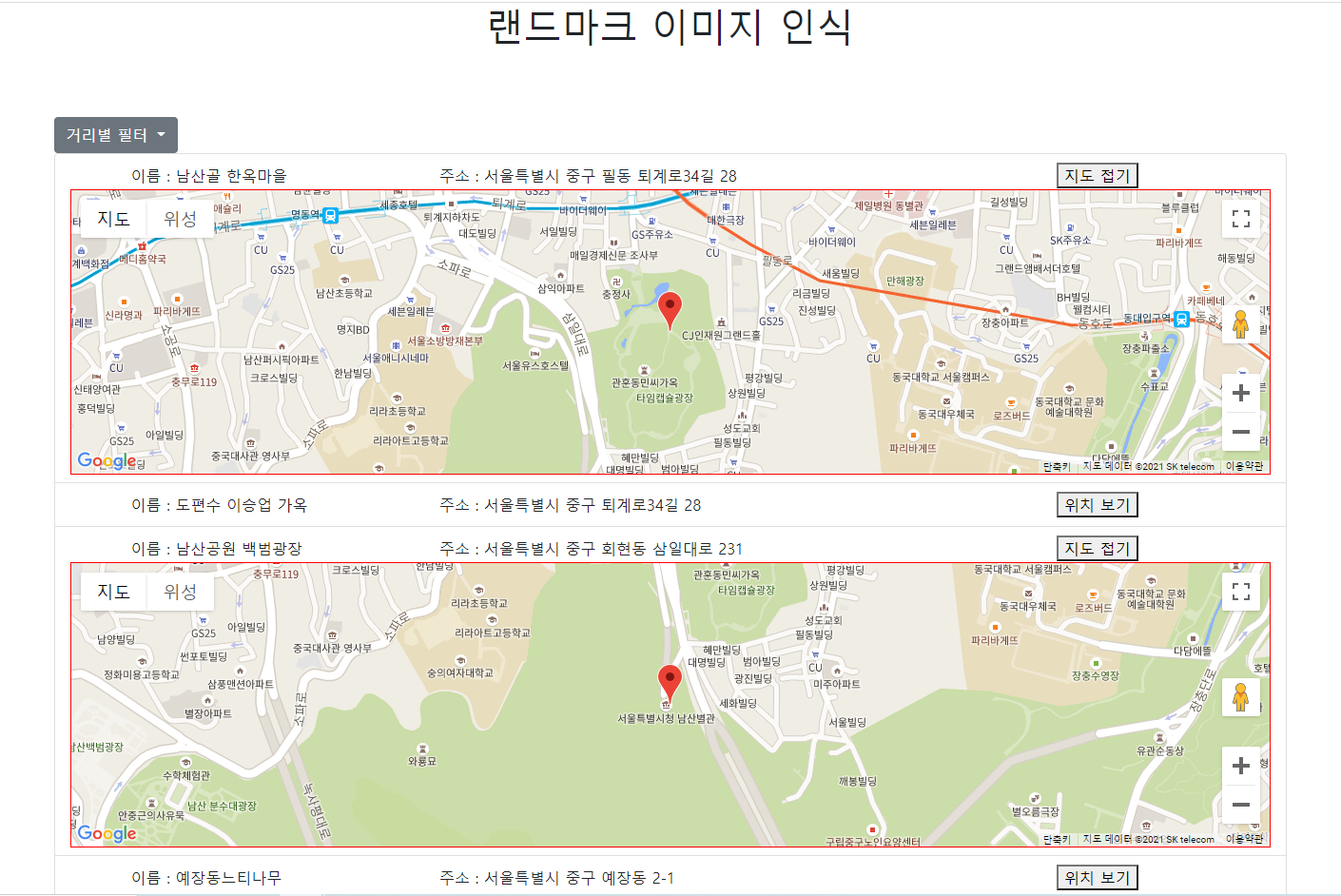
프론트엔드 화면 구성 - 웹 UI
- 1,2일차에 구성해두었던 UI는 다음과 같았다.






- 실제 구현된 화면은 다음과 같다.
이미지 인식 모델
- 프로젝트 리메이크 개요에서 이번 프로젝트를 진행하는 이유의 하나로 다음과 같은것을 꼽았었다.
- AI-HUB에서 받아왔던 랜드마크 이미지에는 해당 이미지에서 랜드마크가 어느 부분을 차지하고 있는지 xy좌표가 기록된 json파일이 동봉되어 있었다.
- 이 좌표를 활용하여 이미지를 crop한 후 학습하면 훨씬 더 좋은 결과물이 나왔겠지만, 모델 제작을 담당하던 팀원이 해당 사실을 인지하지 못한 채 프로젝트가 완성되었다.
- 그 외에도, 이때 당시 EfficientNet을 활용하려 했으나 막히는 부분이 있어 결국 단순 CNN으로 이미지 인식 모델을 구성했었는데,
내 능력이 닿는다면 한번 원래의 목표였던 EfficientNet을 전이학습시킨 모델을 도출하고, 결과를 비교해보고 싶은 마음이 있다.
Crop된 이미지로 정확도를 올려보자
- 우선, crop모델과 non-crop모델의 비교는 CNN모델로 검증했었을 당시(13일차 기록 참조) accuracy가 10%정도의 차이가 있었다.
전이학습 - EfficientNet
- 이후 전이학습 모델의 경우, 계획했던대로 EfficientNet 모델을 전이학습하여 성공적으로 모델을 도출했다.(Test Case 기준 약 90%)
- 하지만 크롤링을 통해 수집한 이미지 데이터셋의 부실함으로 인해 실제로 구한 데이터들과는 다소 맞지 않는 인식 결과를 보여주기도 했다.
(자세한 실험내용은 18일차 기록을 참고)- 물론 18일차의 실험은 챌린지라고 명명한 유달리 이상한 데이터셋들에 대한 실험이었다는 변명도 가능할지 모르나, 데이터셋의 양이 충분했다면 가능했을것도 같다는 가능성을 보았기에 데이터의 부족을 원인으로 꼽고 싶었다.
- 하지만 크롤링을 통해 수집한 이미지 데이터셋의 부실함으로 인해 실제로 구한 데이터들과는 다소 맞지 않는 인식 결과를 보여주기도 했다.
-
18일차 당시, 모델 테스트하는것을 아버지께 보여드렸으나, “서울에 얼마나 갈곳이 많은데 고작 70곳 인식한다고 될 문제냐” 라는 소리를 듣고, 근본적인 클래스 개수 자체의 부족도 고민하게 되었다.
- 생각해보면, 서울 내 유명 대학들(서울대 등등)도 분명 랜드마크의 기준을 충족할텐데, 따로 데이터셋을 모으려 하지 않았다.
SOTA 모델도 전이학습해보자
-
PapersWithCode의 Sota의 경우, 이 글을 작성하고있는 2021년 09월 30일 18시를 기준으로 CoAtNet-7이 차지하고 있다.
Number of params가 무려 2440M에 달한다. -
뿐만 아니라, 정확도 상위 10개 모델 모두 Number of params는 200M을 넘는 수준이었다.
-
내가 훈련시킨 모델인 EfficientNetB7의 Number of params가 64M이었다.
-
Number of params와 훈련시간은 대체로 정비례한다는 점을 생각했을때, 64M으로 훈련에 하루가 걸린 현재의 내 장비로는 훈련에만 한달쯤 걸릴지 모르는 모델은 무리라고 생각한다.
이미지 인식 모델 - 결론
-
원래 목표했던 EfficientNet을 사용한 모델의 전이학습 및 서비스에의 적용은 성공했다.
-
하지만, 데이터셋의 부족으로 인해 모델의 인식률이 떨어졌다.
-
또한, 인식이 가능한 랜드마크 개수가 부족하다는 피드백 역시 받을수 있었다.
반성할 점 + 개선할 점
-
블로그 개설 기념으로 쓴 초창기 글 중에 TDD에 관한 글이 있었음에도 불구하고, 딱히 해당 내용을 사용하지 않았다.
-
Ajax를 통해 한 페이지 안에서 전부 처리가 가능할만한 것들을 괜히 여러페이지 이동하게 만들어버렸다.
- 특히 이부분은 대규모 데이터 로드에 걸리는 로딩시간 문제까지 합쳐져서 개발자인 내가 써보는데도 상당히 안좋은 사용 경험을 주었다.
(식당 데이터만 불러오려 하면 2초간 페이지가 멎어버리는데, 로딩창이라도 띄우던 해야지..)
- 특히 이부분은 대규모 데이터 로드에 걸리는 로딩시간 문제까지 합쳐져서 개발자인 내가 써보는데도 상당히 안좋은 사용 경험을 주었다.
- 데이터 로드 하니 생각난건데, 애당초 관광지 데이터 등을 Django에서 지원하는 sqlite등의 DB에 저장해놨어도 되는거 아닌가 하는 생각 역시 들었다.
-
CSV 파일 읽어서 JSON파일 만들기
vs
sqlite에 들어가있는 데이터 쿼리로 읽어서 JSON파일 만들기 -
어느쪽이 시간이 덜 걸릴지는 일단 만들어 봐야 알것같지만, 후자쪽이 더 빠를것같다는 기분을 도저히 지울수가 없다.
-
-
사소하다면 사소한건데, recommand 페이지의 지도 마커 클릭시 나오는 말풍선에 무슨 데이터를 넣어야 좋을지 계속 고민하고 있다.
-
사적지의 경우 관련 설명을 넣고싶은데, 그렇게 하자니 너무 장문의 데이터가 들어가 직관적이지 않다.
-
그냥 result페이지처럼 심플하게 주소 하나 박아버리고 끝내려니 무언가 아쉬운 기분이고..
-
마커 내부에 html 문법이 작동하던거 봐서는 아예 소개 페이지를 만들어 박을까 싶다가도, 말풍선의 크기를 봐서는 현실적이지 않다고 판단했다.
-
향후 프로젝트 진행 방향
- 모델 추가 실험 진행
- 챌린지 결과 피드백 반영하여 진행.
- 종합운동장 데이터 통합, 양재 시민의 숲 등 다른 숲 데이터 넣고 모델 재생성 및 실험
- 챌린지 결과 피드백 반영하여 진행.
-
병목현상 개선
-
현재 데이터 흐름상 병목현상이 발생하는 구간은 대략 다음과 같을것으로 예상된다.
-
recommand 종류(관광지, 식당, 숙소 등)에 따라 다른 csv를 열고, 해당 데이터를 반복문을 통해 JSON데이터로 가공
-
클라이언트에서 전송받은 JSON 데이터를 반복문을 통해 DOM 객체를 동적생성
-
-
-
프론트엔드 개선
-
지도 마커 데이터 정해서 넣어놓기
-
ajax로 페이지 통합하기
-
데이터 로딩 길어지면 로딩 이미지 띄워줘서 UX 개선하기
-
- 버전 관리
- 완성 버전을 v1으로, 이후 개선 버전을 v2로 두고 git 내부에서 따로 나눠둘 필요가 발생함.
-
데이터 증강
-
이미지 인식 후 오류가 났다고 사용자가 인식했을 시, 사용자가 직접 해당 랜드마크의 이름을 적어 이미지와 함께 제출할수 있도록 하는 피드백 시스템 구축 필요.
-
인식 가능한 랜드마크 클래스 추가.
-