
프로젝트_랜드마크 - 11일차
Trouble Shooting
에러 0. 큰 파일의 github push 오류.
개요
- 어제 글 작성을 마무리하고, 제작한 코드를 pycharm에서 push하려는 순간 push가 거부당했다.
- 100MB이상의 파일을 github에 업로드하려해서 막힌 경우.
- 생성한 데이터셋 (.npz)파일이 100MB를 넘는것이 이유였다.
- 문제는, local repository에 commit할때 .npz파일이 포함되어, commit history를 날려버리지 않는 이상 계속 오류가 날수밖에 없는 상황이었다.
해결(?) 과정
- 방법1.
- 방법2.
- 어차피 혼자 제작하는 프로젝트이니, 리포지토리를 삭제하고 새로 만들었다.
- pycharm에서도 프로젝트를 새로 만들어 코드와 리소스를 붙여넣기 한 후, 리포지토리를 연동하여 해결했다.
- 이걸 해결이라 보긴 애매하지만, 잘 작동하니 해결된것으로 했다.
에러 1.이미지 데이터 ndarray load 오류
개요
- 어제 잠들기 전까지 계속 연구했었던 ndarray 문제.
- 저장된 npz파일에서 뽑아낸 array가 tensor로 변환되지 않던 문제.
해결 과정
- 낮에 맨정신으로 코드를 다시 살펴보던 도중, npz로 파일을 저장하는 코드에서
xy = (X_train, X_test, Y_train, Y_test)로 묶어주는 부분을 제거하고,
np.savez('./img_data_crop.npz',X_train=X_train,X_test=X_test,Y_train=Y_train,Y_test=Y_test)와 같이 세이브할때 인수를 넣어준 다음,
with np.load('./img_data_crop.npz',allow_pickle=True) as data: X_train = data['X_train'] Y_train = data['Y_train'] X_test = data['X_test'] Y_test = data['Y_test']으로 데이터를 호출하니 tensor로 변환할수 없다는 오류메세지는 출력되지 않았다.
- 조금 더 조사해본 결과, 이런 튜토리얼을 확인할수 있었다.
- 내용을 요약하면, tensor 연산을 하면 ndarray는 자동으로 tensor로 변환된다는것이었다.
- 여태 내가 겪은 에러들의 경우, 한차례 데이터가 묶여있어 이상하게 출력이 되는것이 원인이었던것.
에러 2. Dst tensor is not initialized.
개요.
- 에러1을 해결하자 대신 나타난 에러 메시지이다.
해결 과정
- 구글링을 하자, 이런 글을 발견할수 있었다.
- 해당 글에서는 원인을 크게 두가지로 설명한다.
- GPU의 메모리 부족
- 잘못된 차원의 dataset이 input됨
- 해당 글에서는 원인을 크게 두가지로 설명한다.
- GPU 메모리 부족으로 간주하고, batch-size를 줄이는 등의 작업을 진행했으나 여전히 메모리 부족현상이 관찰됨.
- 오류가 나는 코드인
test_dataset = tf.data.Dataset.from_tensor_slices((X_test,Y_test))를 중점으로 조사한 결과, stackoverflow의 글 하나를 발견할수 있었다.
- 해당 글에 따르면, 내가 사용하고 있던
from_tensor_slices는 소량의 데이터를 가공하는데에만 유용하기 때문에 메모리 에러가 발생한다고 한다. - 해당 글에서는 TFRecodeDataSet을 활용하는 방안을 제시해주어서, 해당 내용에 대해 학습하고 적용해보기로 했다.
- 해당 글에 따르면, 내가 사용하고 있던
TFRecord?
- 참고한 글
- Tensorflow로 기계학습을 할 때, 학습 데이터 세트를 읽어들이는 방법은 네가지가 존재한다.
- 사전에 메모리를 모든 데이터에 로드
- Python 코드로 조금씩 읽어들여가면서 feed_dict그래프에 입력한다.
- TFRecord로부터 그래프상에 Threading과 Queues를 활용하면서 읽는다
- Dataset API를 사용한다.
-
1번은 데이터 세트가 작을때는 고속으로 데이터를 그래프에 입력하는것이 가능하나, 데이터가 큰 경우 메모리 부족이 발생해 속도가 낮아지거나, 메모리 할당 오류가 발생한다.
-
2번은 싱글 스레드를 사용할 경우, 데이터 읽어들이기와 학습을 동시에 하게 되는 경우가 발생해 전체 학습 시간이 길어진다.
-
TFRecord를 사용한다면 3번이나 4번의 방법으로 Tensorflow 그래프에 입력하게 된다.
- 예제를 아무리 찾아보아도 제대로 적용할수가 없어, 기본적인 텐서플로우의 파이프라인에 대해 이해하고 넘어갈 필요를 느꼈다.
Tensorflow 파이프라인 개념정리
- Tensorflow의 튜토리얼의 내용을 기반으로 작성했다.
데이터세트 생성
- 데이터 소스
- 메모리 또는 하나 이상의 파일에 저장된 데이터로부터 Dataset을 구성
- tf.data.Data.from_tensors()
- tf.data.Dataset.from_tensor_slices()
- tf.data.TFRecordDataset()
- 입력데이터가 TFRecord 형식일때 사용.
- 메모리 또는 하나 이상의 파일에 저장된 데이터로부터 Dataset을 구성
- 데이터 변환
- 하나 이상의 tf.data.Dataset 객체로부터 데이터 세트를 구성
- Dataset.map()
- 요소별 변환
- Dataset.batch()
- 다중 요소 변환
- Dataset.map()
- 하나 이상의 tf.data.Dataset 객체로부터 데이터 세트를 구성
데이터 세트의 정의 및 특징
- 데이터세트 = 동일한 중첩 구조를 가지는 시퀀스.
- 중첩 구조
- tuple
- dict
- NamedTuple
- list(단, tf.stack을 사용한 명시적 구성 필요)
- 중첩 구조
- 데이터세트는 tf.TypeSpec에 의해 표현된다.
- 데이터 세트의 종류
- tf.Tensor
- tf.sparse.SparseTensor
- tf.RaggedTensor
- tf.TensorArray
- tf.data.Dataset
- …
- 데이터 세트의 종류
- Dataset.element_spec를 사용하여 구조 확인 가능.
입력 데이터 읽기
- Numpy 데이터 읽기
- Dataset.from_tensor_slices()가 가장 간단.
- 하지만, 오늘 결과를 봤듯이, 큰 데이터는 메모리 부족으로 오류가 발생한다.
- Dataset.from_generator()
- 파이썬 generator를 활용해 데이터를 읽어들인다.
- from_generator에 파이썬 generator callable함수를 인수로 넣어 tf.data.Dataset으로 변환한다.
- Python GIL의 영향을 받는다.
- Python GIL이란?
- 간단히 말해서, 멀티스레딩이 안된다는 소리.
- Python GIL도 중요한 개념같아보이니 언젠가 따로 정리해봐야겠다.
- from_generator()의 예시로 제시된 ImageDataGenerator를 활용해 데이터셋의 생성을 성공할수 있었다.
- 굳이 numpy를 통해 따로 데이터셋을 생성하려던 나의 시도가 헛수고가 되어버렸지만, 그래도 된다는 사실이 기쁘다.
- Dataset.from_tensor_slices()가 가장 간단.
공부를 위해 정리하는것 역시 좋지만,
지금 당장은 작업이 급하기 때문에 정리는 여기까지만 진행하고, 나중에 프로젝트 완료후 되짚어보는 방식으로 정리하도록 해야겠다.
ImageDataGenerator
- tf.keras.preprocessing.image.ImageDataGenerator
- 하위의 함수들과 함께 사용하여 이미지 데이터를 데이터셋으로 변환한다.
- 이번에 사용한것은 flow_from_directory 함수다.
- 상위 디렉터리를 입력받아 하위 디렉터리를 class로 하는 데이터셋을 생성한다.
- 파이프라인 튜토리얼에서 함께 언급된 from_generator까지 활용한 최종 코드는 다음과 같다.
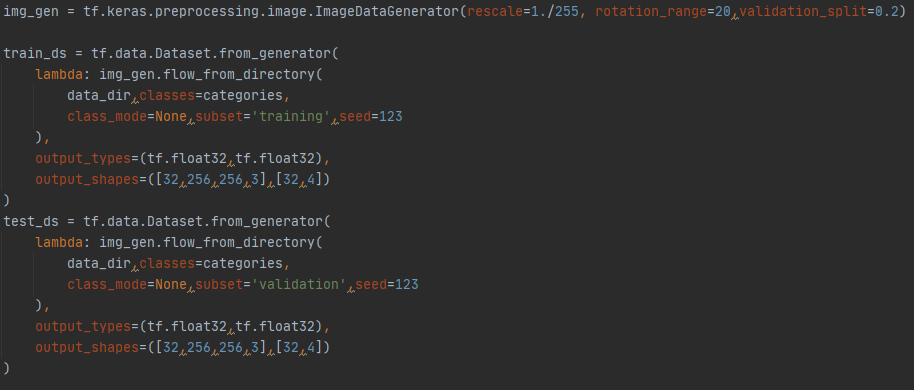
다음 할 일
- 생성한 이미지셋을 모델에 넣고 학습시키려 했으나, Shape mismatch에러가 발생했다.
- 어제까지는 밥숟가락도 안들던 아기를 보는 기분이라면,
오늘은 한숟가락 먹고 맛없다고 뱉어내는 아기를 보는 기분이다. - 학습이라도 하려 했다는것에 일단 기뻐하기로 했다.
- 어제까지는 밥숟가락도 안들던 아기를 보는 기분이라면,
- Shape mismatch에러면 분명 차원수 맞추기에 관련된 문제일테니, 구글링과 노가다를 통해 디버깅해야겠다.